en16931-data-extractor
Data Extractor for the European e-Invoice Specification (EN16931)
Summary
Open sourced for the creators of the EU e-invoice specification to allow easier sanity checks of the data within the syntax binding tables (within EN16931-3-2 and EN16931-3-3) to improve the quality of the CEN specification. Build as part of the PrototypeFund project “paperless” to generate larger parts of the software implementing the European e-invoice specification (EN16931).
Background
The EU e-Invoice Specification (EN16931)
There is a wonderful online introduction for EN16931 given by the EU and great presentation slides from CEF.
Reason for this Software
The specification EN16931 is meant to build e-invoice software, but it is tedious and error prone to read the PDF (or paper) specification and manually copy its data. The goal of this tool is to extract the main data, the so called syntax-binding (mapping) between the XML formats and the Semantic Data Model from more structured office documents. The bindings are for instance required to generate source code for a software allowing to load/save both XML formats. In addition our future software shall modify/create XML by an API based on the Semantic Data Model of EN16931. Some reasoning behind from a developers bird perspective: There are three graphs within the EU specification:
- Graph: Semantic Data Model (describes the user semantic both XML are being mapped upon)
- Graph: UBL XML - W3C XML grammar (describes all allowed XML files of UBL)
- Graph: UN/CEFACT CII XML - W3C XML grammar (describes all allowed XML files of UN/CEFACT)
The syntax bindings - that this tool is extracting - are connecting “graph 2” with “graph 1” and “graph 2” with “graph 3”. In addition, aside of the grammar there are more restrictions upon the XML that W3C Schema is not able to express (given by ISO Schematron constraints), for instance an order date has to be earlier than the pay date. These schematron restrictions can be seen as additional relations upon the XML grammar graphs (graph 2 & graph 3). It is planned to map those XML constraints later to the “Semantic Data model” level (graph 1). By this it could be validated if there are constraints only for UBL or UN/CEFACT and missing for the other XML. Also the same restrictions on the semantic graph might be reused for other older e-invoice formats to be mapped to the Semantic Data Model, in other words the validation artefacts could be easier reused.
Specification EN16931-3: Details on Syntax Binding
The EU e-invoice specification demands the support of two XML file formats OASIS UBL 1.2 and UN/CEFACT XML Industry Invoice D16B.
In its 3rd part (EN16931-3) - the deliverable of WG 3 of CEN TC434 - the EU specification binds the XML syntax with the EU e-invoice semantic via an 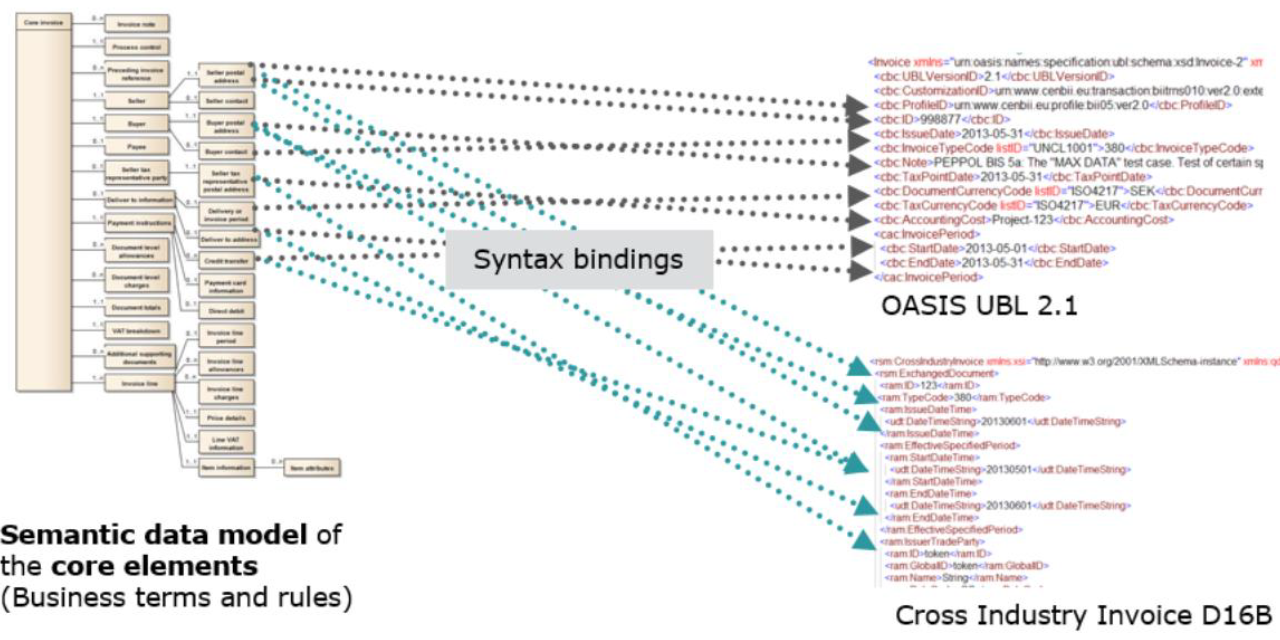
For each syntax exist a document, which contains at least two mapping table (normative & informative).
- The first “normative table” (see below) describe the syntax binding from the semantic (light grey) to XML (dark grey),
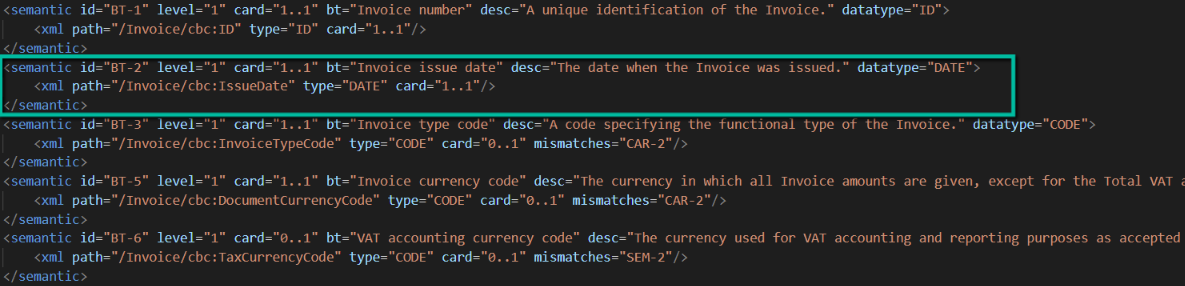
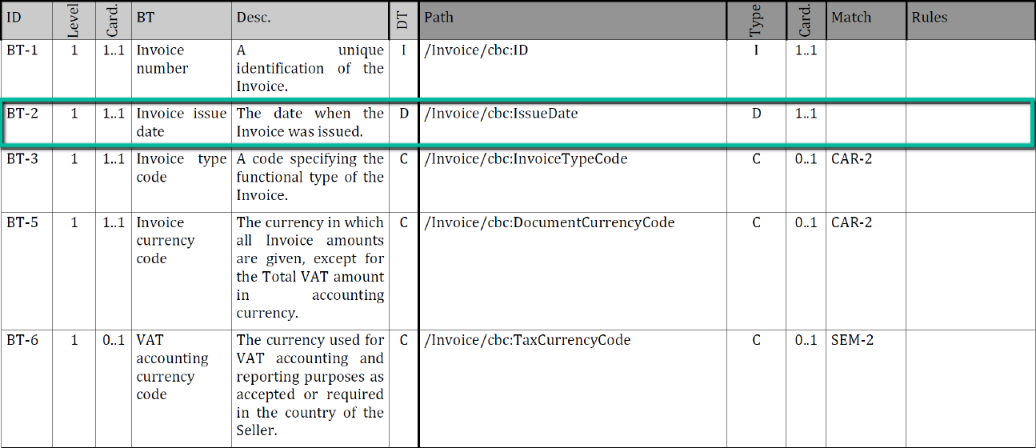 Below the desired access to the normative syntax binding as structured XML data instead of PDF (digital paper/stone).
Below the desired access to the normative syntax binding as structured XML data instead of PDF (digital paper/stone).
- The second “informative table” (see below) describes it the other way around from XML (dark grey) to semantic (light grey).
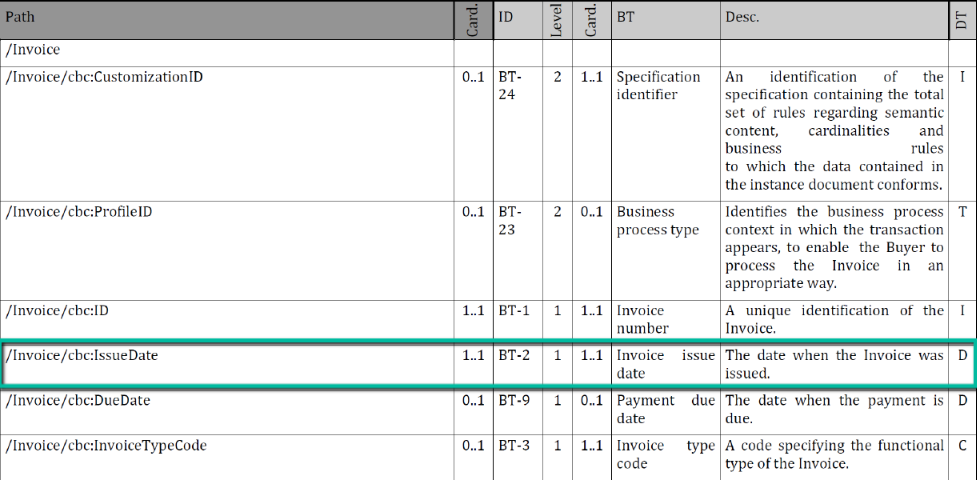 The informative table (here Table 3) does not add any new information compared to its preceding sibling the normative table (here Table 2). The informative table starts with the XML part (dark grey), but uses only two of the five XML attributes from the prior normative table.
NOTE: In theory, the exact complete data of the informative table should already exist in the preceding normative table.
The informative table (here Table 3) does not add any new information compared to its preceding sibling the normative table (here Table 2). The informative table starts with the XML part (dark grey), but uses only two of the five XML attributes from the prior normative table.
NOTE: In theory, the exact complete data of the informative table should already exist in the preceding normative table.
The above images where overtaken from public EU webinar slides.
Software: EN16931 Data Extractor
The data extractor is a simple Java tool that can be called from command line. It reads from one or more office documents of EN16931-3 the containing syntax binding (or mapping) tables. For each table, each row is being split into the:
- XML part (dark grey)
- Semantic part (light grey)
The data of each table is being saved in an own XML format to ease reading and testing the data set. This new XML structure is straight forward: A list of semantic entities, each containing the corresponding XML elements as their children.
NOTE: To ease comparison of a “normative table” from the specification with it’s (hopefully identically) “informative table” twin, which has fewer XML columns, the normative table is being saved twice, once with all information and a second time as a subset equal to the informative table infoset, making file comparison easier.
Software Prerequisites
Running (everybody, e.g. CEN Technical Writer)
Building (developers)
NOTE: There is an own chapter for software developers about the software.
Usage
Extracting the Data
- Download the JAR with all dependencies includes en16931-data-extractor-20230523-jar-with-dependencies.jar
- To see version information via command-line call: “java -jar en16931-data-extractor-20230523-jar-with-dependencies.jar”
- Save the CEN DOCX documents of EN16931-3 as ODT (tested with LibreOffice 6.2.5.2 on Ubuntu 19.04 (disco) via commandline: ‘libreoffice –headless –convert-to odt *.docx’)
NOTE: I do not use the DOCX files, but save them to ODT as I worked for 20 years on the OpenDocument format (and predecessors) and maintain an ODF library.
- To extract data from the specification via command-line call and move the output into a text file:
“java -jar en16931-data-extractor-20230523-jar-with-dependencies.jar specification.odt (or directory) > log.txt”
Data Analysis
-
The extracted data can be found at three locations aside the input document:
- For each table of EN16931-3, which defines a syntax binding, an XML file was saved in a folder named equal to the specification name.
- For each syntax-binding the data-set of the informative syntax-binding table and its preceding normative table data-set (which has the suffix _SUBSET as it does not save all XML columns), a folder “_SAME_BINDING_<Format>” has been created with the identical XML files within.
- Every semantic data-set of each syntax binding table is being saved as XML within the “SAME_SEMANTIC folder.
-
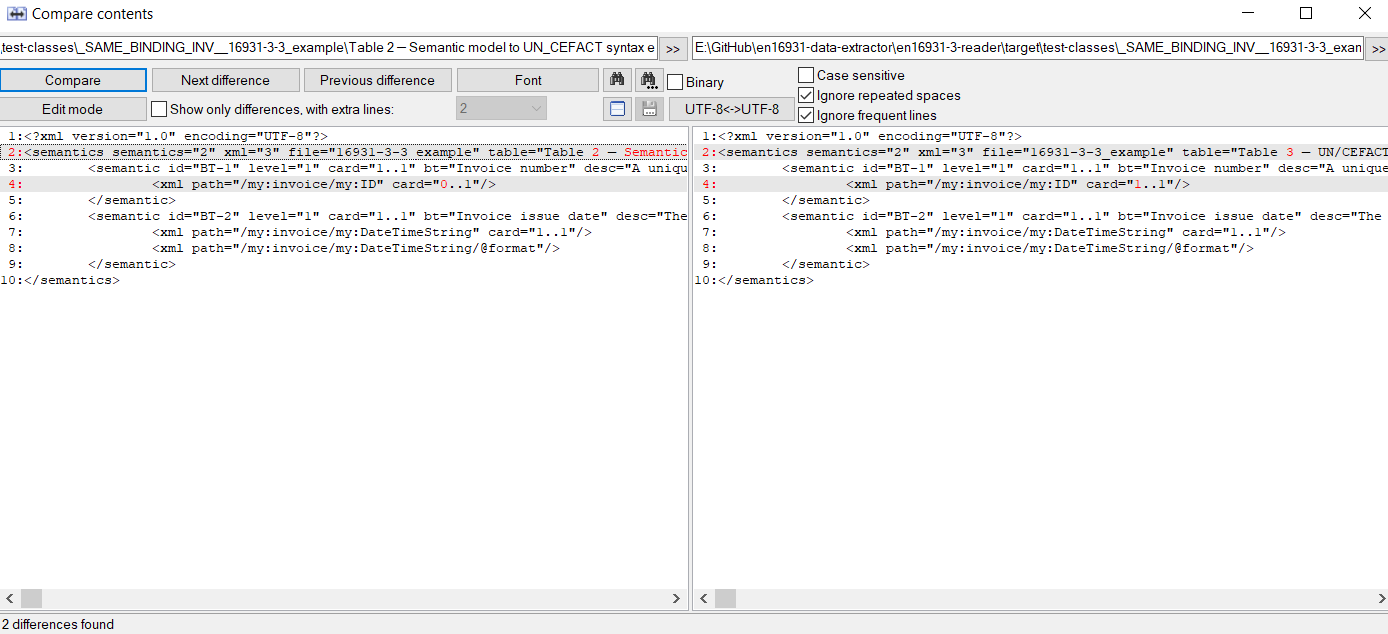
Use a text file comparing tool like Total Commander on Windows (MENU:Files -> Compare By Content) to detect the differences between the “informative” and its twin the “normative SUBSET” XML file.
Example:
The picture below - using fictitious data - shows a data set with a problem, as aside of the heading bearing the two table names is different between the two tables, the XML cardinality shall not be different between normative and informative syntax binding table:
Participation
Pull requests are most welcome! :-)
Please note that this README.md is being generated. The version number and paths to the JAR are being replaced by automation during every build (ie. ‘mvn install’). The README.md to edit can be found at <ROOT>/site/README.md.
The reason for this was to automate not only the build, but also the deployment of the JAR with all dependencies for the user (see usage section above). For this reason the revision number from the <ROOT>/pom.xml - I am using the date - is being added to the generated artefacts and the artefacts (JARs & documentation) are being copied to the github site directory (ie. <ROOT>/docs).